Vincent Bernat: Git as a source of truth for network automation
The first step when automating a network is to build the source of
truth. A source of truth is a repository of data that provides the
intended state: the list of devices, the IP addresses, the network
protocols settings, the time servers, etc. A popular choice is
NetBox. Its documentation highlights its usage as a source of
truth:
Why Git?
If we look at how things are done with servers and services, in a
datacenter or in the cloud, we are likely to find users of
Terraform, a tool turning declarative configuration files into
infrastructure. Declarative configuration management tools like
Salt, Puppet,1 or Ansible take care of server
configuration. NixOS is an alternative: it combines package
management and configuration management with a functional language to
build virtual machines and containers. When using a Kubernetes
cluster, people use Kustomize or Helm, two other declarative
configuration management tools. Tapped together, these tools implement
the infrastructure as code paradigm.
NetBox intends to represent the desired state of a network versus its operational state. As such, automated import of live network state is strongly discouraged. All data created in NetBox should first be vetted by a human to ensure its integrity. NetBox can then be used to populate monitoring and provisioning systems with a high degree of confidence.When introducing Jerikan, a common feedback we got was: you should use NetBox for this. Indeed, Jerikan s source of truth is a bunch of YAML files versioned with Git.
Why Git?
If we look at how things are done with servers and services, in a
datacenter or in the cloud, we are likely to find users of
Terraform, a tool turning declarative configuration files into
infrastructure. Declarative configuration management tools like
Salt, Puppet,1 or Ansible take care of server
configuration. NixOS is an alternative: it combines package
management and configuration management with a functional language to
build virtual machines and containers. When using a Kubernetes
cluster, people use Kustomize or Helm, two other declarative
configuration management tools. Tapped together, these tools implement
the infrastructure as code paradigm.
Infrastructure as code is an approach to infrastructure automation
based on practices from software development. It emphasizes
consistent, repeatable routines for provisioning and changing
systems and their configuration. You make changes to code, then use
automation to test and apply those changes to your systems.
Kief Morris, Infrastructure as Code, O Reilly.
A version control system is a central tool for infrastructure as code.
The usual candidate is Git with a source code management system like
GitLab or GitHub. You get:
- Traceability and visibility
- Git keeps a log of all changes: what, who, why, and when. With a
bit of discipline, each change is explained and self-contained. It
becomes part of the infrastructure documentation. When the support
team complains about a degraded experience for some customers over
the last two months or so, you quickly discover this may be related
to a change to an incoming policy in New York.
- Rolling back
- If a change is defective, it can be reverted quickly, safely, and
without much effort, even if other changes happened in the meantime.
The policy change at the origin of the problem spanned over three
routers. Reverting this specific change and deploying the
configuration let you solve the situation until you find a better
fix.
- Branching, reviewing, merging
- When working on a new feature or refactoring some part of the
infrastructure, a team member creates a branch and works on their
change without interfering with the work of other members. Once the
branch is ready, a pull request is created and the change is ready
to be reviewed by the other team members before merging. You
discover the issue was related to diverting traffic through an IX
where one ISP was connected without enough capacity. You propose and
discuss a fix that includes a change of the schema and the templates
used to declare policies to be able to handle this case.
- Continuous integration
- For each change, automated tests are triggered. They can detect
problems and give more details on the effect of a change. Branches
can be deployed to a test infrastructure where regression tests are
executed. The results can be synthesized as a comment in the pull
request to help the review. You check your proposed change does not
modify the other existing policies.
Why not NetBox?
NetBox does not share these features. It is a database with a REST
and a GraphQL API. Traceability is limited: changes are not grouped
into a transaction and they are not documented. You cannot fork the
database. Usually, there is one staging database to test modifications
before applying them to the production database. It does not scale
well and reviews are difficult. Applying the same change to the
production database can be hazardous. Rolling back a change is
non-trivial.
Update (2021-11)
Nautobot, a fork of NetBox, will soon
address this point by using Dolt, an SQL database engine allowing
you to clone, branch, and merge, like a Git repository. Dolt is
compatible with MySQL clients. See Nautobots, Roll Back! for a
preview of this feature.
Moreover, NetBox is not usually the single source of truth. It
contains your hardware inventory, the IP addresses, and some topology
information. However, this is not the place you put authorized SSH
keys, syslog servers, or the BGP configuration. If you also use
Ansible, this information ends in its inventory. The source of
truth is therefore fragmented between several tools with different
workflows. Since NetBox 2.7, you can append additional data with
configuration contexts. This mitigates this point. The data is
arranged hierarchically but the hierarchy cannot be
customized.2 Nautobot can manage configuration contexts in
a Git repository, while still allowing to use of the API to fetch
them. You get some additional perks, thanks to Git, but the
remaining data is still in a database with a different lifecycle.
Lastly, the schema used by NetBox may not fit your needs and you
cannot tweak it. For example, you may have a rule to compute the IPv6
address from the IPv4 address for dual-stack interfaces. Such a
relationship cannot be easily expressed and enforced in NetBox. When
changing the IPv4 address, you may forget the IPv6 address. The source
of truth should only contain the IPv4 address but you also want the
IPv6 address in NetBox because this is your IPAM and you need it to
update your DNS entries.
Why not Git?
There are some limitations when putting your source of truth in Git:
- If you want to expose a web interface to allow an external team to
request a change, it is more difficult to do it with Git than
with a database. Out-of-the-box, NetBox provides a nice web
interface and a permission system. You can also write your own web
interface and interact with NetBox through its API.
- YAML files are more difficult to query in different ways. For
example, looking for a free IP address is complex if they are
scattered in multiple places.
In my opinion, in most cases, you are better off putting the source of
truth in Git instead of NetBox. You get a lot of perks by doing
that and you can still use NetBox as a read-only view, usable by
other tools. We do that with an Ansible module. In the remaining
cases, Git could still fit the bill. Read-only access control can be
done through submodules. Pull requests can restrict write access: a
bot can check the changes only modify allowed files before
auto-merging. This still requires some Git knowledge, but many teams
are now comfortable using Git, thanks to its ubiquity.
-
Wikimedia manages its infrastructure with Puppet. They
publish everything on GitHub. Creative Commons uses
Salt. They also publish everything on GitHub.
Thanks to them for doing that! I wish I could provide more
real-life examples.
-
Being able to customize the hierarchy is key to avoiding
repetition in the data. For example, if switches are paired
together, some data should be attached to them as a group and not
duplicated on each of them. Tags can be used to partially work
around this issue but you lose the hierarchical aspect.
Update (2021-11) Nautobot, a fork of NetBox, will soon address this point by using Dolt, an SQL database engine allowing you to clone, branch, and merge, like a Git repository. Dolt is compatible with MySQL clients. See Nautobots, Roll Back! for a preview of this feature.
Why not Git?
There are some limitations when putting your source of truth in Git:
- If you want to expose a web interface to allow an external team to
request a change, it is more difficult to do it with Git than
with a database. Out-of-the-box, NetBox provides a nice web
interface and a permission system. You can also write your own web
interface and interact with NetBox through its API.
- YAML files are more difficult to query in different ways. For
example, looking for a free IP address is complex if they are
scattered in multiple places.
In my opinion, in most cases, you are better off putting the source of
truth in Git instead of NetBox. You get a lot of perks by doing
that and you can still use NetBox as a read-only view, usable by
other tools. We do that with an Ansible module. In the remaining
cases, Git could still fit the bill. Read-only access control can be
done through submodules. Pull requests can restrict write access: a
bot can check the changes only modify allowed files before
auto-merging. This still requires some Git knowledge, but many teams
are now comfortable using Git, thanks to its ubiquity.
-
Wikimedia manages its infrastructure with Puppet. They
publish everything on GitHub. Creative Commons uses
Salt. They also publish everything on GitHub.
Thanks to them for doing that! I wish I could provide more
real-life examples.
-
Being able to customize the hierarchy is key to avoiding
repetition in the data. For example, if switches are paired
together, some data should be attached to them as a group and not
duplicated on each of them. Tags can be used to partially work
around this issue but you lose the hierarchical aspect.
- Wikimedia manages its infrastructure with Puppet. They publish everything on GitHub. Creative Commons uses Salt. They also publish everything on GitHub. Thanks to them for doing that! I wish I could provide more real-life examples.
- Being able to customize the hierarchy is key to avoiding repetition in the data. For example, if switches are paired together, some data should be attached to them as a group and not duplicated on each of them. Tags can be used to partially work around this issue but you lose the hierarchical aspect.
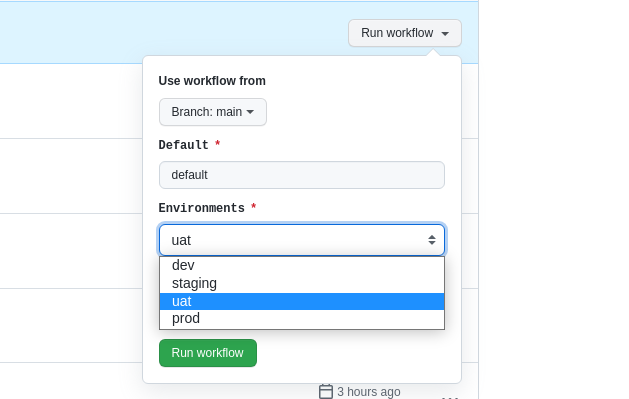
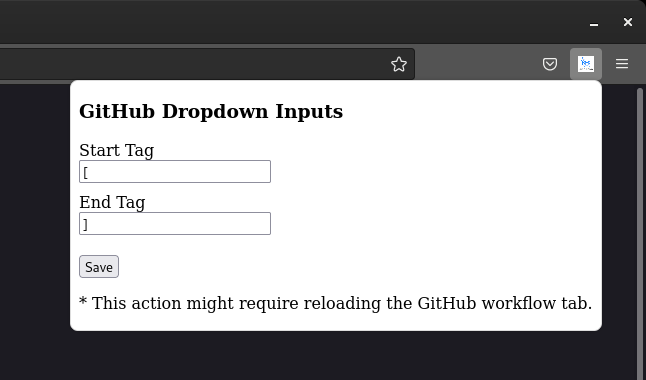
 So I decided to create a solution for this, always thinking about simplicity and in a way that makes it easy to get this missing functionality. I started by creating an input array pattern using
So I decided to create a solution for this, always thinking about simplicity and in a way that makes it easy to get this missing functionality. I started by creating an input array pattern using 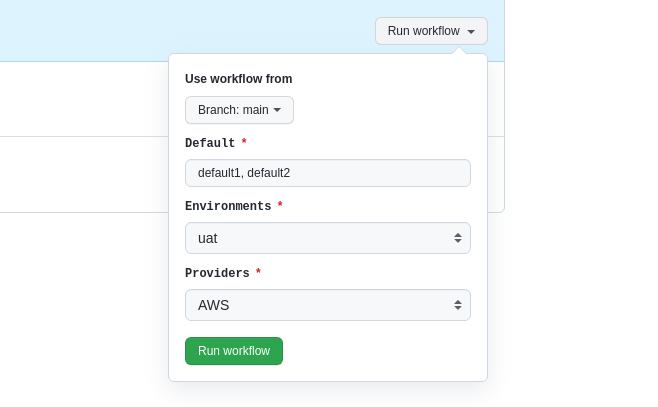



 If I have seen further, it is by standing on the shoulders of Giants Issac Newton, 1675. Although it should be credited to 12th century Bernard of Chartres. You will know why I have shared this, probably at the beginning of Civil Aviation history itself.
If I have seen further, it is by standing on the shoulders of Giants Issac Newton, 1675. Although it should be credited to 12th century Bernard of Chartres. You will know why I have shared this, probably at the beginning of Civil Aviation history itself.
 But yes, it needs it own space, maybe after some more time.
But yes, it needs it own space, maybe after some more time.

 Although I'm about 5 months early and we're in the middle of a terrible heat
wave where I live, I've just finished building my new winter bicycle!
I've been riding all year round for about 8 years now and the winters in
Montreal are harsh enough that a second winter-ready bicycle is required to
have a fun and safe cold season.
I'm saying "new bicycle" because a few months ago I totaled the frame of my
previous winter bike. As you can see in the picture below (please disregard the
salt crust), I broke the seat tube at the lug.
I didn't notice it at first and while riding I kept hearing a "bang bang" sound
coming from the frame when going over bumps. To my horror, I eventually
realised the sound was coming from the seat tube hitting the bottom bracket
shell!
Although I'm about 5 months early and we're in the middle of a terrible heat
wave where I live, I've just finished building my new winter bicycle!
I've been riding all year round for about 8 years now and the winters in
Montreal are harsh enough that a second winter-ready bicycle is required to
have a fun and safe cold season.
I'm saying "new bicycle" because a few months ago I totaled the frame of my
previous winter bike. As you can see in the picture below (please disregard the
salt crust), I broke the seat tube at the lug.
I didn't notice it at first and while riding I kept hearing a "bang bang" sound
coming from the frame when going over bumps. To my horror, I eventually
realised the sound was coming from the seat tube hitting the bottom bracket
shell!
 I'm sad to see this
I'm sad to see this  Summer has just started and I'm already looking forward to winter :)
Summer has just started and I'm already looking forward to winter :)
 In the last few months I presented several talks. Topics ranged from a round table on free
software, to sharing some of my work as SRE in the Cloud Services team at the Wikimedia Foundation.
For some of them the videos are now published, so I would like to write a reference here, mostly as
a way to collect such events for my own record. Isn t that what
In the last few months I presented several talks. Topics ranged from a round table on free
software, to sharing some of my work as SRE in the Cloud Services team at the Wikimedia Foundation.
For some of them the videos are now published, so I would like to write a reference here, mostly as
a way to collect such events for my own record. Isn t that what 




 Like many I use
Like many I use  Too much has been written, a war of support letters is going on, Debian is heading head first like Lemmings into the same war. And then, there is this by the first female President of the American Civil Liberties Union (ACLU):
Too much has been written, a war of support letters is going on, Debian is heading head first like Lemmings into the same war. And then, there is this by the first female President of the American Civil Liberties Union (ACLU):
 A long time, no blog entries. What's prompted a new missive?
Two things:
A long time, no blog entries. What's prompted a new missive?
Two things:
 Context:
Context:
 At the Wikimedia Foundation they configure basically all servers with IPv4/IPv6 dual stack, at
least in the control plane interface (those used for SSH management, etc). IPv6 is not supported
yet on the Cloud Services dataplane (openstack), but it will in the near future.
An elegant solution for this IPv4/IPv6 dual stack configuration in the control plane is to embed
the IPv4 address into the IPv6 address, something like this:
At the Wikimedia Foundation they configure basically all servers with IPv4/IPv6 dual stack, at
least in the control plane interface (those used for SSH management, etc). IPv6 is not supported
yet on the Cloud Services dataplane (openstack), but it will in the near future.
An elegant solution for this IPv4/IPv6 dual stack configuration in the control plane is to embed
the IPv4 address into the IPv6 address, something like this:
